
GPU utilization with neural networks
Abstract
Nowadays GPUs are widely used for neural networks training and inference. It’s clear that GPUs are faster than CPU, but how much and do they do their best on such tasks. In this article we’re testing performance of the basic neural network training operation—matrix-vector multiplication using basic and kind of top GPUs, AWS p2.xlarge instance concretely, to see whether they are doing well in such operations. We compare different approaches, such as usage of ready-to-use computation frameworks such as TensorFlow, cuBLAS as well as handwritten code using CUDA. We’re figured out that on basic hardware, such as NVIDIA GeForce 840M installed on my laptop, speedup is not so significant compared to CPU, but NVIDIA K80 card gives quite a good speedup. However there was found that GPU computational facilities is not fully exploited on such operations and resulting performance is not even close to the maximum.
Intro
Recently we decided to try RNN in our project and started investigation in this direction. I used high-level machine learning framework Keras for this purposes. After first try, even though I use GPU for training (TensorFlow backend for Keras), it was quite a long time to fit the network for dozens of epochs on quite a tiny dataset. All this computations was done on my GPU-enabled laptop with NVIDIA GeForce 840M card—not a best choice, but convenient for the first try.
Recently we decided to try RNN in our project and started investigation in this direction. I used high-level machine learning framework Keras for this purposes. After first try, even though I use GPU for training (TensorFlow backend for Keras), it was quite a long time to fit the network for dozens of epochs on quite a tiny dataset. All this computations was done on my GPU-enabled laptop with NVIDIA GeForce 840M card—not a best choice, but convenient for the first try.
Then I tried to fit the network with the same architecture and dataset on Amazon’s p2.xlarge instance with NVIDIA K80 on-board. It was three times faster, but it’s only three times.
So, the natural question was: if we’re planning to exploit such networks on big amounts of data, what is the plan to scale this process in terms of time and expenses? How to decide, what’s cheaper and more effective for us: cluster of AWS instances m4.16xlarge with 64 vCPUs, or one instance p2.16xlarge with 16 GPUs on-board.
So, the plan is to measure performance in Flops on matrix by vector multiplication—basic operations in neural network fitting and prediction process.
Our goal is to measure if utilization of GPU hardware is close to the optimal.
Measurements
First of all I wrote a set of little programs to measure performance in Gflops for such a basic neural network operation. So, here’s the set of tests for matrix by vector multiplication I used:
- cuBLAS’s cublasSgemv() function call;
- CUDA simple kernel;
- CPU implementation in a single thread;
- CPU implementation in multiple threads;
- Implementation using TensorFlow and Python;
- Python + Numpy.
The test implementation takes one parameter, size, make makes the operation of multiplication of matrix ℝN×N by vector ℝN. I expect 2⋅N2 floating point operations for this task—N2 multiplications and N2 additions.
Performance measure for cuBLAS and CUDA were done by asynchronous putting kernels into a stream, start and end of execution were marked with CUDA events to make precise evaluation of time that was spent on kernels execution.
Here’s the graphs I get running these tests on my laptop and on p2.xlarge AWS instance. They show dependence between N—the size, mentioned in the paragraph above,—and achieved performance in Gflops. Also random fill operations and memory transfers are not included into a benchmark, so it’s just a pure computation time.
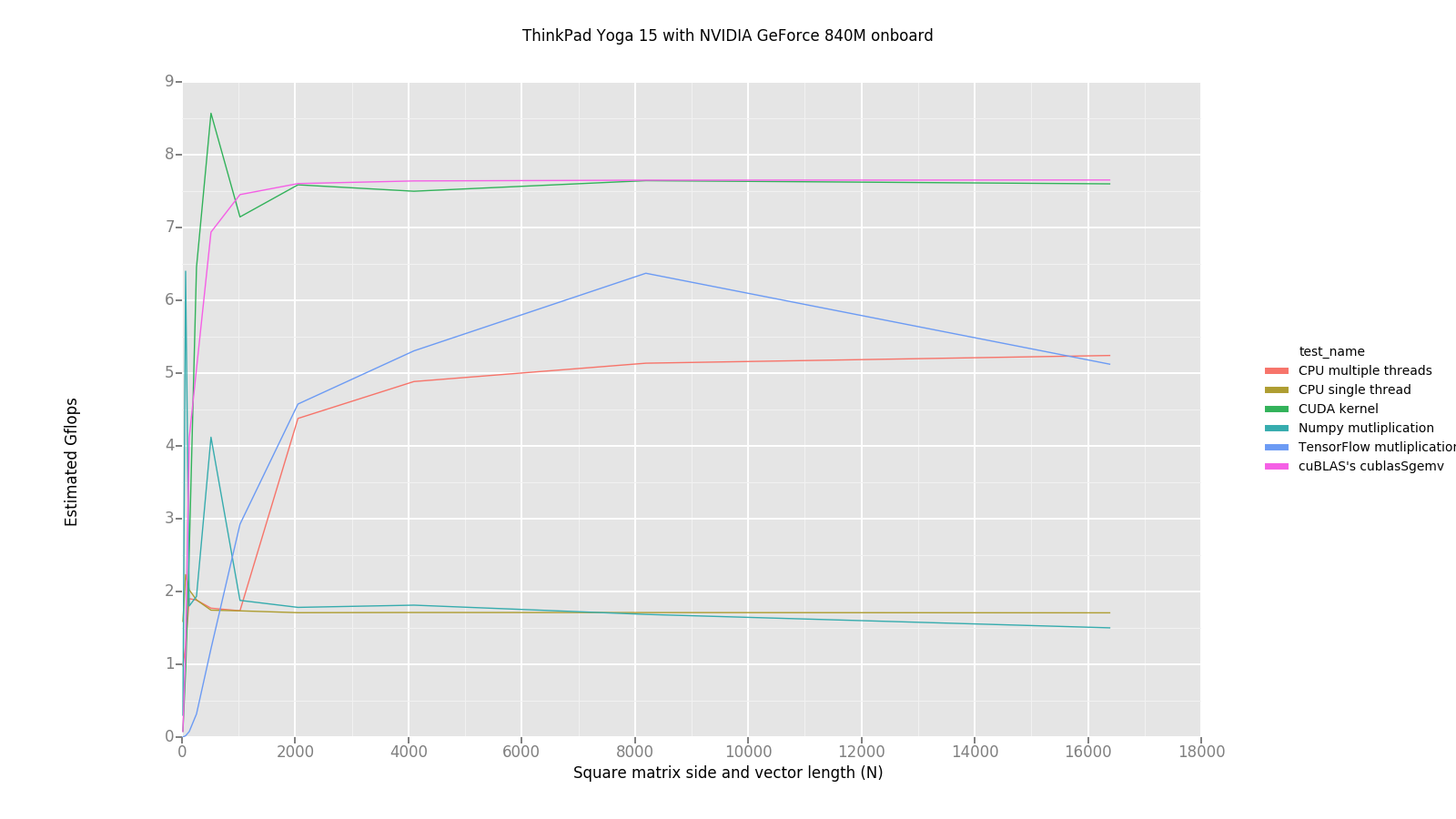
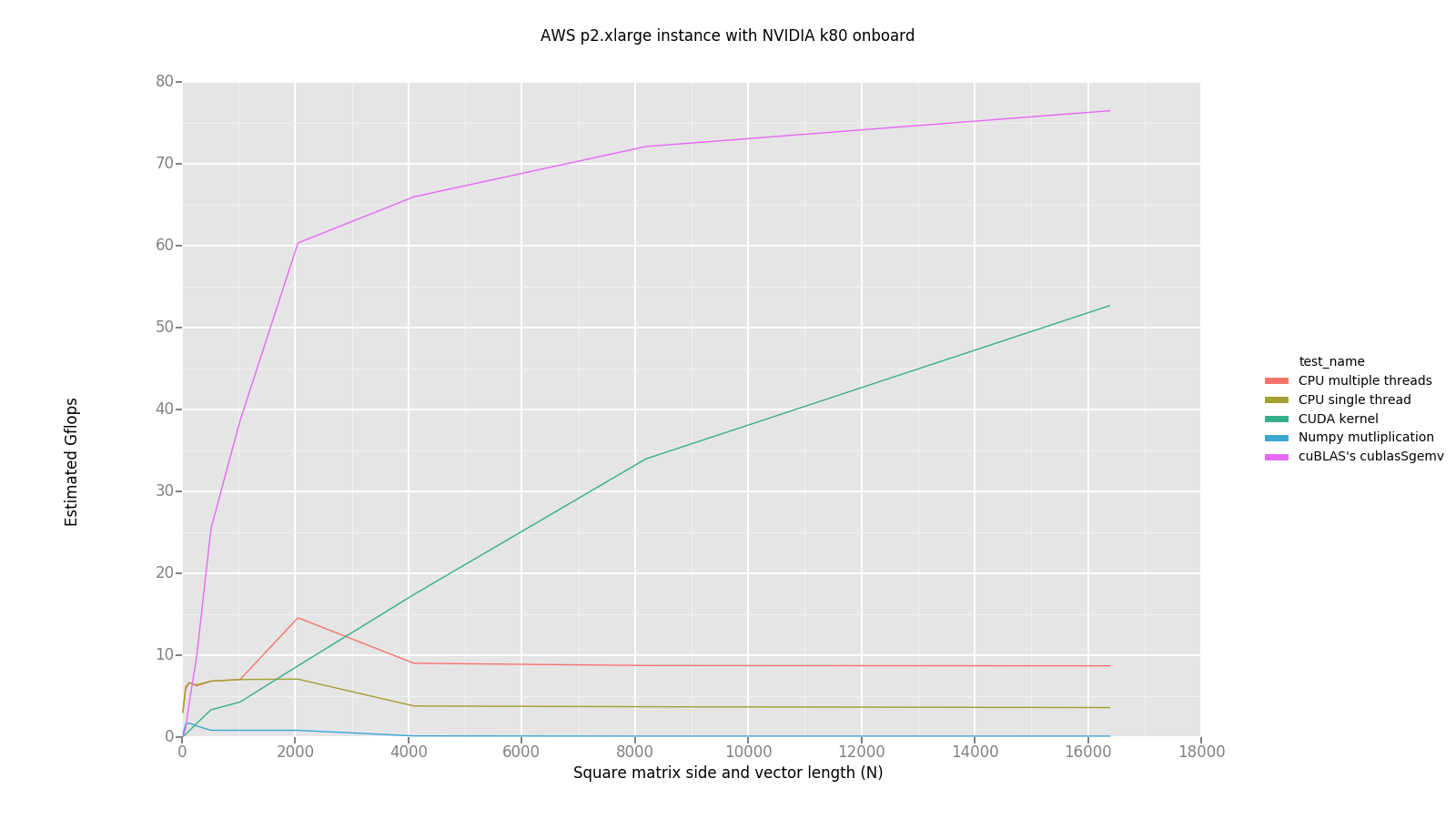
I faced problems running TensorFlow on AWS instance, so it’s omitted on the graph.
Also it looks like CUDA implementation performance was not saturated, so I decided to test where it’s saturated, running just GPU test for this purposes, not to spend a lot of time:
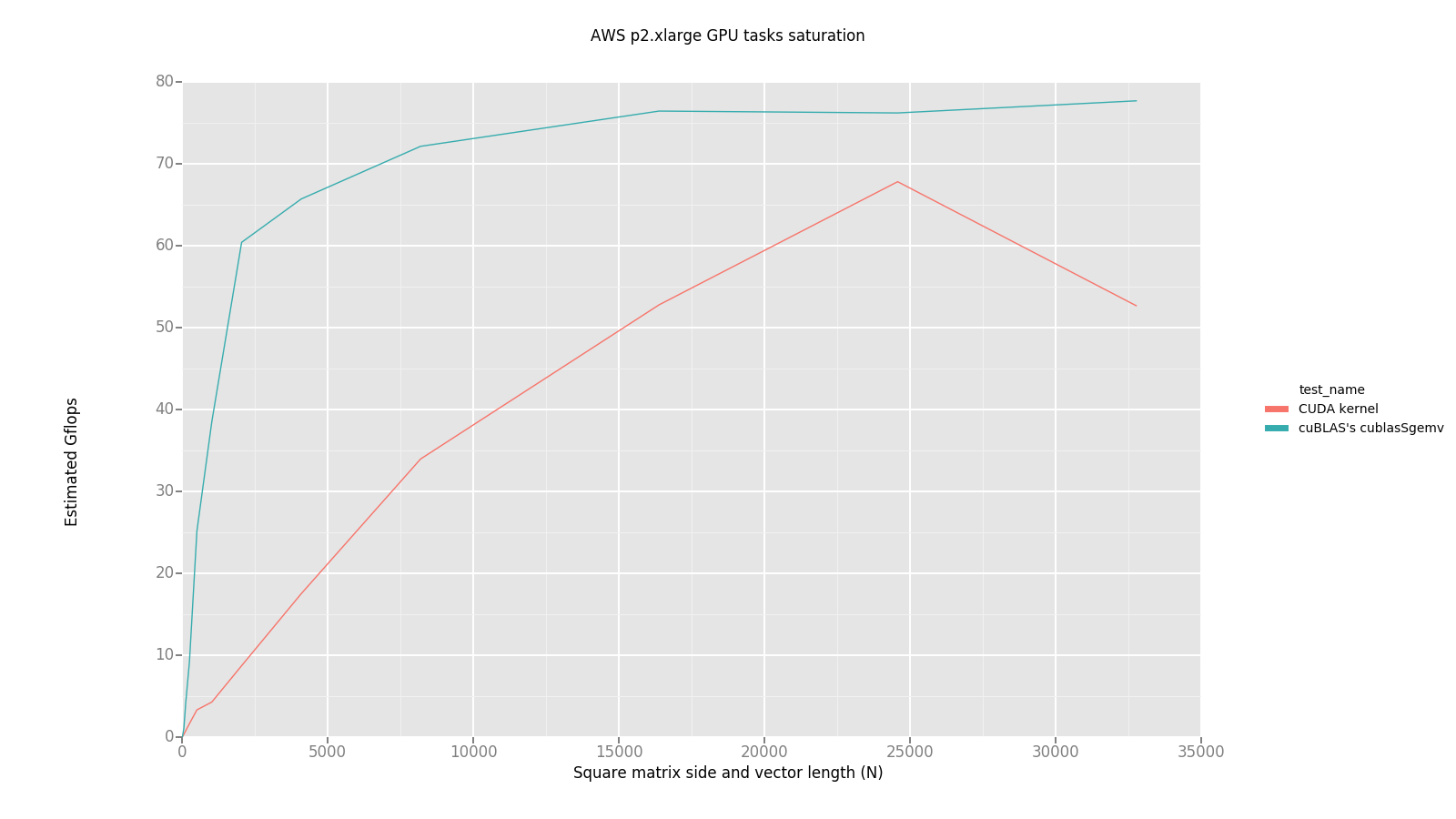
Strange things about these graphs is that Numpy dot product on AWS instance is much slower than single-threaded implementation. I did not dig too much in this direction to explain why.
Performance in Gflops for N=16384 for my laptop and AWS p2.xlarge instance. We see, that there’s only 1% of declared higher performance for both GPUs reached.
| Test name | ThinkPad Yoga 15 with NVIDIA GeForce 840M onboard, Gflops | AWS p2.xlarge instance with NVIDIA K80 onboard, Gflops |
|---|---|---|
| cuBLAS’s cublasSgemv | 7.65234 | 76.4771 |
| CUDA kernel | 7.59958 | 52.6853 |
| CPU single thread | 1.70727 | 3.60644 |
| CPU multiple threads | 5.24184 | 8.70136 |
| Numpy dot product | 1.50101 | 0.12011 |
| TensorFlow multiplication | 5.12266 | — |
What we see in general is that there’s no huge performance boost running matrix vector multiplications on GPU against CPU, but still significant—∽10 times faster on AWS instance and ∽1.5 times on my laptop (looks weird either).
After all I compared the maximum performance with the theoretical maximum performance for both cards, and there’s huge gap between what we’ve got and what we see. For NVIDIA K80 theoretical performance is 5591–8736 Gflops, for NVIDIA GeForce 840M is 790.3 Gflops.
So, it’s discouraged me in some way, even though I understand that these are theoretical maximums, but real world picture gives performance drop nearly 100 times, it’s 1% of declared maximum.
This time I decided to write a dummy CUDA kernel with a lot of computations and minimum reads and writes with respect to the number of computational operations. It gave me the numbers I was looking for:
Maximum achieved Gflops
| Device | Achieved performance, Gflops | Theoretical maximum, Gflops |
|---|---|---|
| NVIDIA K80 | 3982.4 | 5591–8736 |
| NVIDIA GeForce 840M | 793.187 | 790.3 |
Looks much better, but it means that we can achieve such performance only by huge amount of operations with respect to the number of reads and writes from/to global device memory.
Also note that on AWS p2.xlarge instance we have only a half of NVIDIA K80, so the number in table is quite a natural.
Conclusions
We suspect that matrix-vector multiplication operations are limited not by computational power of GPU, but much more by memory latency. It looks like usage GPUs for machine learning purposes is not the ideal solution, but the best available nowadays. Also looks like we were not the first who faced this problem, and we found that Google came up with theirs own Tensor Processing Unit. It’s a special hardware for machine learning tasks with more power and computational efficiency. More technical details can be found here.